ccf问答匹配比赛
这两周玩了一下ccf 2020 中的房产聊天问答匹配比赛,虽然还没完赛,但是先总结一下目前的收获。
比赛说明
首先,这个比赛的任务是在一系列回答中找到针对客户问题的回答。而客户提问前的对话及回答前的对话都是不可见的,即整个IM信息是不连续的,任务就是在不连续的回答中找到那些针对客户问题的答案。样本示例:
1 | query: 采荷一小是分校吧。 |
可以看到,样本中所谓的针对问题的回答,不仅仅是直接回答问题的答案,而是更有针对性和说明的回答。
baseline
模型选择上,baseline全部使用bert,鉴于相对位置编码优于绝对位置编码,所以选择NEZHA作为预训练权重。备选方案Roberta。
qa pair
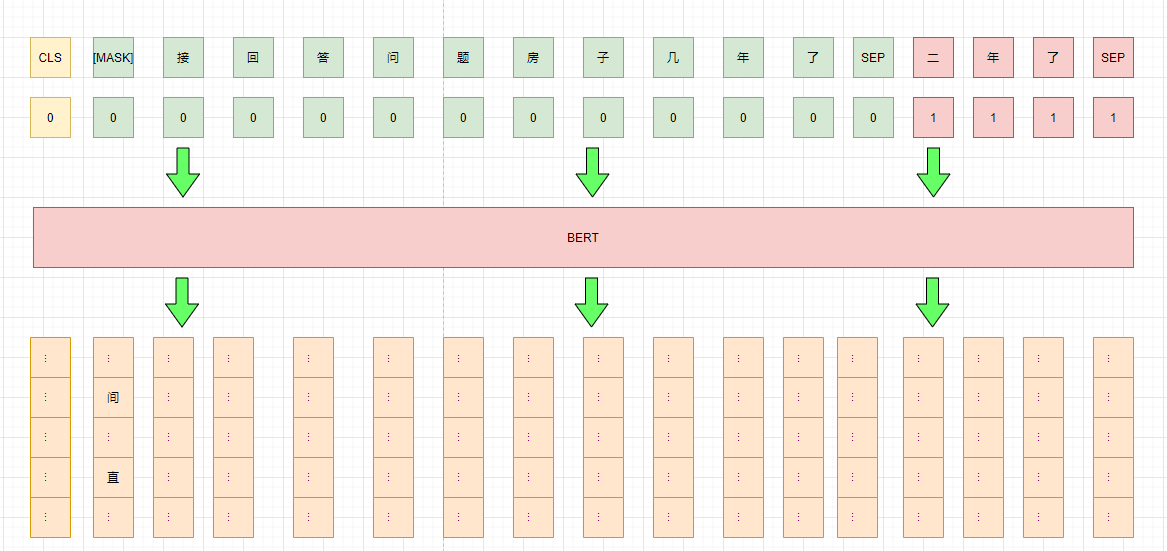
由于回答是不连续的,所以可以将问题和答案一一对应,组成qa pair,然后分别判断是否是针对问题的回答。
point
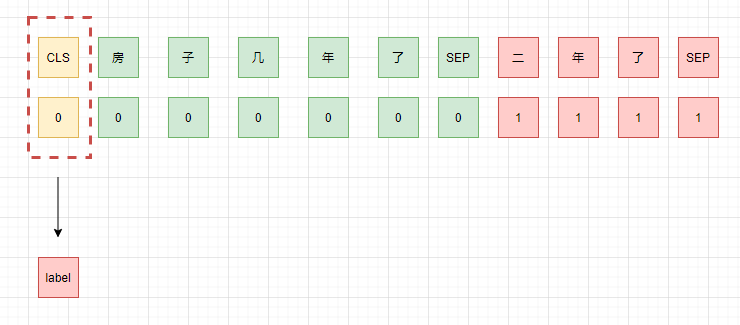
虽然对话是不连续的,但是是同一个对话,所以不同的回答能相互支撑,提供部分信息,所以,第二种思路就是将同一个问题的所有回答都拼接在当前回答后面,然后同时对每一个回答进行判断。
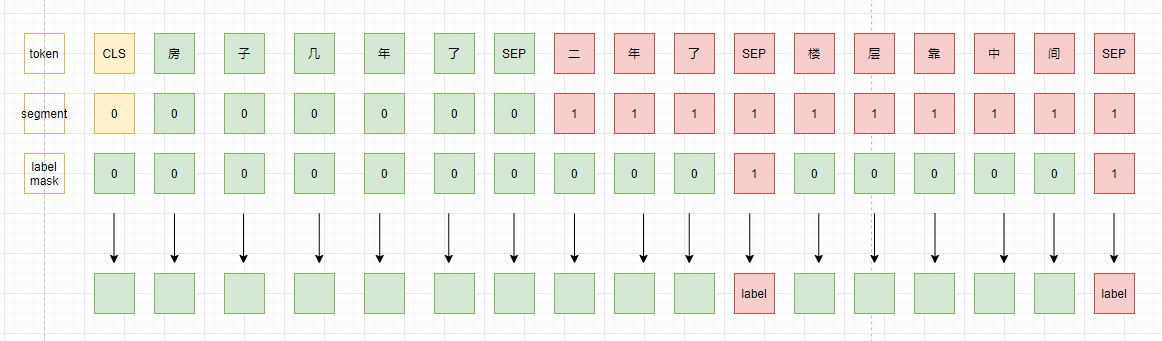
pet
由于预训练模型使用的语料与当前任务所处领域有一定的gap,所以一个比较简单的想法是先在任务语料上进行Post-training,然后再进行fine-tuning。不过,上次我们介绍过Pattern-Exploiting Training,不了解的可以参考PET-文本分类的又一种妙解。借鉴PET的方式,我们将posting-training与fine-tuning结合,即在label data上进行pattern exploiting training,在unlable data上进行mlm任务进行post-traing.
以上三种baseline的代码放在ccf_2020_qa_match,感兴趣的可以查阅。
update: concat
由于bert 不同的transformer 层提取到的语义粒度不同,而不同粒度的信息对分类来说起到的作用也不同,所以可以concat所以粒度的语义信息,拼接后作为特征进行分类。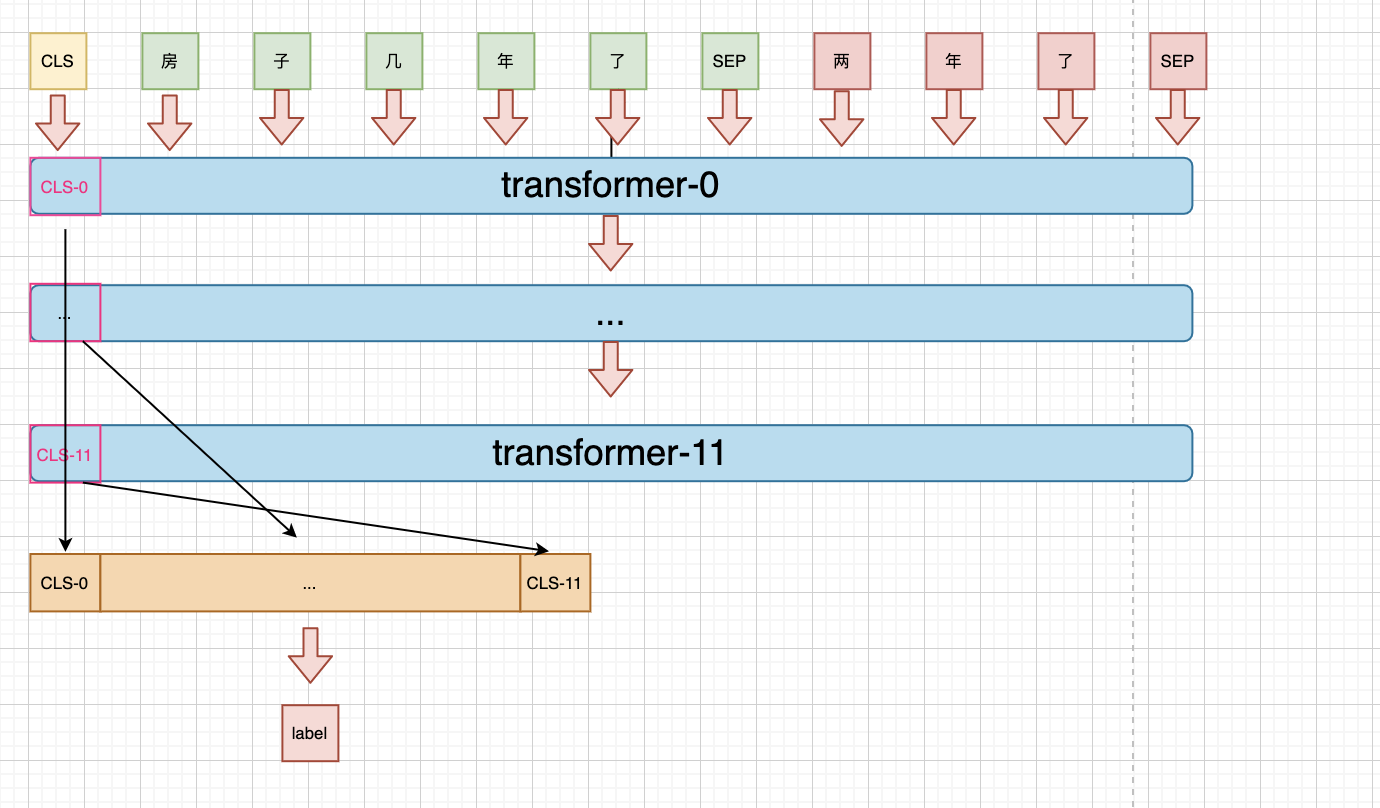
对比
第一种方案(pair-wise),由于缺少一定的上下文信息,加上很多回答都非常短,同时又可能会离提问”较远”,所以效果是最差的,不过线上提交单模型也有0.75左右了,所以bert确实强大!
第二种方案(point)中,将所有已知的上下文信息都整合到一起,所以相对上一种有所提升,不过由于这种上下文的可见性,所以也会带来一定的迷惑:即对某一个reply来说,假如其他的reply中有一个是针对性的回答,就有可能会干扰对当前reply的判断。
第三种方案(pet)中,通过mlm进行post-training,可以将领域间的gap缩小,同时,由于在训练时”看到”了测试数据,也在一定程度上减小了线上线下的差距,所以性能是最好的,单模型最好能达到0.765左右。
尝试
Post-training
第一个想法是尝试进行post-training,来提升所有方案的性能。由于问答之间是不连续的,所以在组织语料上进行了不同方式:
- query-reply pair
- query-reply-list pair
- cut-sentence to make pair
以上文提到的样本为例;
- query-reply pair:
1 | 采荷一小是分校吧。 |
- query-reply-list pair
1 | 采荷一小是分校吧。 |
- cut-sentence to make pair
1 | 采荷一小 |
第一种,将同一对话作为同一篇文档顺序排列;第二种,将问题作为单独文档,同一问题的所有回答作为单独文档,第三种,将问题和回答都作为单独文档,同时将其拆分为左右两个部分来做nsp任务。
在mask选择上,选择动态mask,即每个epoch都重新选择mask的token。
最终结果是如果直接使用[CLS]做最终特征,以上三种都不能带来pair-wise方案的提升,反而会带来不小的降低,猜测原因可能与以上三种方式的nsp任务与当前任务的模式不同,所以反而会引起降低。而在bert 后面接其他层(AttentionPooling1D,DGCNN)后能带来大约一个点左右提升。
focal loss
由于针对性回答与非针对性回答在数量上有不小差距,大约3:1,所以也想到尝试在loss上进行调节。
最终结果是没有多少提升,最后将普通loss训练后的模型在train data上进行了predict,并借鉴之前focal loss中的方式分析了一下,画出对应的难易样本分布。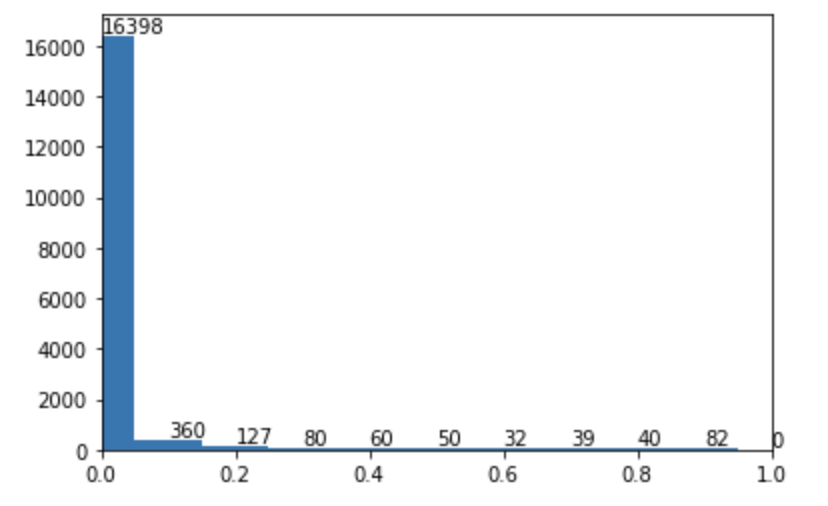
上图中不难发现其难样本并不多也不聚集,所以focal loss并不能带来提升。
对抗训练与梯度惩罚
对抗训练与梯度惩罚也是两种比较有效的提升模型泛化性能的方法。其中对抗采用的FGM。
最终实验后发现两者都能带来线上线下的提升,尤其是对抗,最高能提升三个点,不过相同参数下结果也会差二个点左右,所以每个模型都要少不了调参的过程,所以适合后期提高时使用。
tricks
由于也是第一次做比赛,所以走了不少弯路,也学到了一些trick:
- 对样本进行kfold然后训练,得到k个模型再进行ensemble。其中k从5增加到10,也会有提升。这种方式的好处是可以让更多的数据参与到训练,同时多个模型进行投票,也会带来或多或少的提升。
- 对数据进行post-training,虽然我的尝试暂时没有起到提升,但是交流时有其他组的同学通过这个方法就达到单模型0.77以上。而我三种方案对比,pet的方式也是最好的,所以也在一定程度上说明这种方式的有效性。
- bert后接新的层,如cnn,dgcnn等。虽然bert的特征提取能力强大,但是在bert后面接一些新的层,总能带来一定的提升,尤其是DGCNN。这种方式可以看作是两种模型的stacking,即利用bert做特征提取,后面的模型在其上做下游任务。
- 不同模型进行ensemble,如将上述三种方案进行ensemble,由于不同模型关注点不同,融合后会带来一定提升。
- 更大的模型,如bert-xxlarge等。虽然我的显卡没法实验这种方案,但是交流后发现很多同学都是使用的大模型,baseline就可以达到0.77以上了,所以有时候还是需要一些”钞能力”.
- 数据清洗与增强。交流中有人提到用外部数据做增强,所以如果有能力,先做清洗与增强,结果也会提升很多。
总结
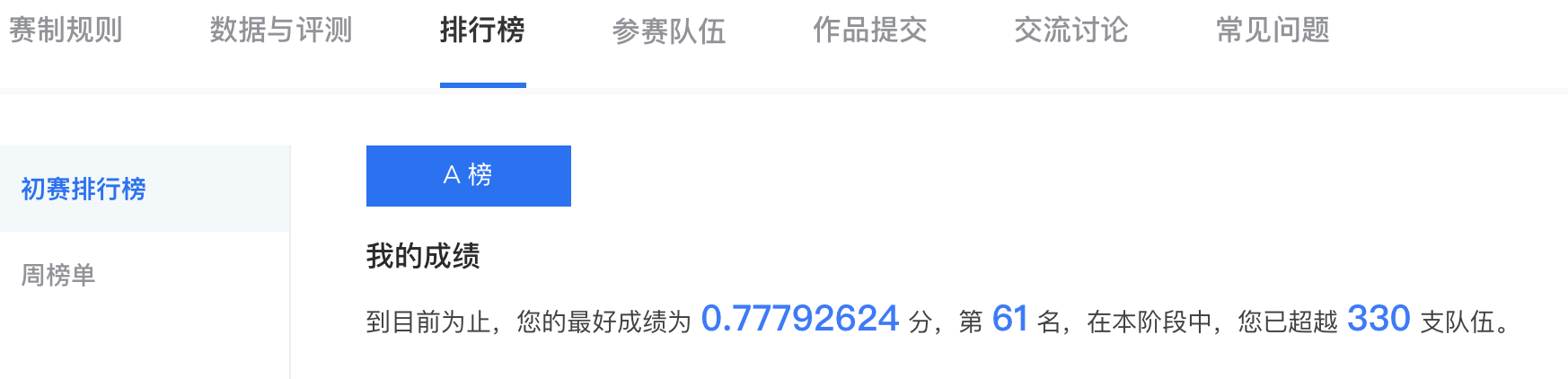
以上就是对当前比赛的一些思考与总结,现在单模型最好的成绩为线上0.7779, 虽然只排到61名,不过鉴于我使用的是base模型,同时也是单模型,没有任何其他后续处理,所以结果感觉还行。后续完赛后如果有新的收获再更新一篇吧。最后,附上暂时排名截图。
关于头图
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
