NLP中的数据增强
数据增强
数据增强技术已经是图像领域的标配了,如旋转、镜像、翻转等。由于图像本身的特性,通过这些操作后生成的图像虽然与原始图像不同,但其图像的内容确实基本一致的。所以可以增强模型的鲁棒性和泛化能力。
而在NLP领域情况确是不同的,因为NLP中改变一个词有可能变为语义完全想反的句子,比如:"这好吃吧" -> "这好吃吗".
所以,NLP中数据增强主要有两种方式:一种是保持语义的数据增强,一种是可能破坏语义的局部扰动增强。
保持语义数据增强
保持语义的数据增强主要是构造与原句子语义一样的新句子,如回译、生成等。
回译
回译即将句子从当前语种翻译至新的语种,然后再翻译回来,得到语义相同表达不同的句子。如将句子从中文翻译为英文然后再翻译回中文。可以借助各大互联网平台的免费API来完成。除此之外,还可以多翻译几组中间语种,增加其丰富性。
生成
生成的方式即通过样本构建一个生成模型,生成与样本语义相同的句子。如Learning to Ask Unanswerable Questions for Machine Reading Comprehension 就是通过生成新的问题来做SQuAD2.0. 此外,之前的文章利用NLG 增强QA 任务性能里也总结了通过生成问题及问题答案对来增强qa模型性能,不熟悉的可以翻看一下。
由于两种方式构造的新句子都是与原句子语义相同的句子,所以,这种方式进行数据增强表达模型偏好是:模型应对于不同表达形式的同一语义的文本具有不变性。
局部扰动
局部扰动主要包括同义词替换、插入、删除、互换四种操作,出自论文EDA: Easy Data Augmentation Techniques for Boosting Performance on
Text Classification Tasks,因为操作简单,所以也叫EDA(Easy Data Augmentation)。下面分别介绍一下这四种策略。
同义词替换
从句子中随机找出1个非停用词,并求出其同义词,然后用同义词替换该词,重复n次操作
插入
从句子中随机找出一个非停用词,并求出其同义词,然后将同义词插入句子中的一个随机位置,重复n次操作。
删除
以概率p,随机删除句子中的每一个单词
互换
随机选择句子中的两个词,然后互换其位置,重复n次。
此外,论文中给出了替换删除等操作的比例$\alpha$ 与新增句子数量$n$ 的建议值: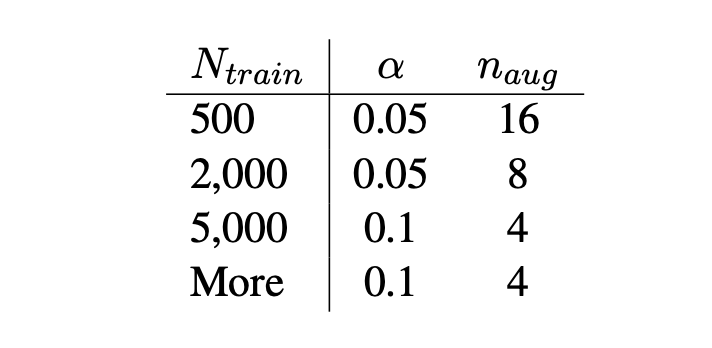
而现在我们通常都使用bert等transformer模型做下游任务,所以删除操作可以使用padding,即删除token但保留其占位,即保留其位置编码;互换操作可以选择更大的span进行;插入和同义词替换操作也可以尝试从当前句子选择一个词代替同义词等。
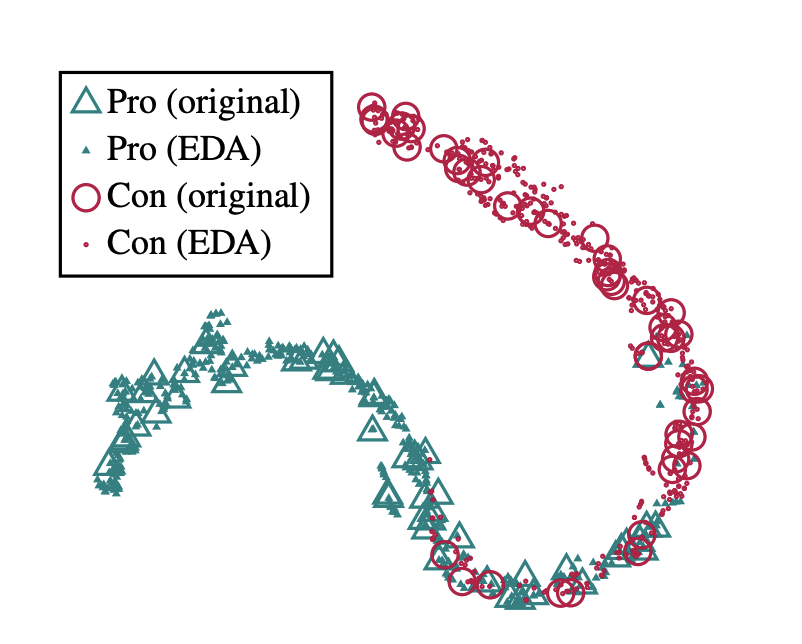
文章开头我们也提到了,对句子中的词进行改变时,很可能得到语义完全相反的句子,那上面这四种方式为何有效呢?首先,句子中引入的新词都是同义词,所以语义不会发生很大的变换,其次,论文作者通过分析发现,虽然构造的新句子变得可能都不是一个通顺的句子了,但其特征空间分布下的label并没有发散,即经过EDA变换后,原始数据一方面引入了很多噪声,扩大了数据集,同时又保持了原有的标签,因而有效的扩大了样本集的信息容量。
此外,上面的方式相当于对模型增加了一个正则约束,其所表达的模型偏好是:模型应该对文本的局部噪声不敏感
总结
以上就是当前NLP中常用的几种数据增强方案,尤其在样本不均衡及小样本任务下,数据增强往往能带来非常不错的提升。所以值得尝试。
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
