
Knowledge Distillation (3) : 看样本下菜的FastBERT
之前Knowledge Distillation 相关的两篇分别介绍了两种知识蒸馏的方式:模型替换之bert-of-theseus 和知识迁移,本篇介绍一种从样本入手的知识蒸馏方法。
Knowledge Distillation 目的
再来看看我们做knowledge distillation 的目的是什么:我们是想要模型即性能好又推理快,那要推理快,我们直接使用一个更小的模型,比如3层的bert就比12层的bert快,那为什么不这么做呢?这是因为直接用3层bert来fine-tuning的结果往往不那么“性能好”,所以他只能满足推理快这一半。
所以我们要通过一个teacher 来引导这个小模型,来把“性能好”这个特性补上。
怎么做
而一般做KD ,我们往往关注怎么去让student 更好的学习teacher,但是好像没人关注过student 直接fine-tuning 的时候到底有多差?拿文本分类来说,我们用bert-3 在IFLYTEK数据上进行fine-tuning,最终的accuracy 大概在57.9%,而bert-12 大概在60.7%((结果)[https://github.com/xv44586/toolkit4nlp/blob/master/examples/classification_ifytek_bert_of_theseus.py]),3层是不如12层,但是差距只有不到3个点,换句不严谨的话说,只有不到3%的数据需要12层的bert才能达到当前最优性能,而大部分样本在前3层就已经能确定了。
换成一句我们都能理解的事实描述就是:样本有难易之分,有的样本容易区分,有的样本不容易区分。这时候,如果全部样本都当不容易区分看待,对这部分容易区分的样本来说就是“杀鸡用牛刀”了,那一个简单直观的办法就是,我们“杀鸡时用杀鸡刀,杀牛时用杀牛刀”,即我们按样本难易程度,分别为他们指定不同的模型来分类,简单的样本只需要用小模型,因为他就能得到与大模型一致的结果,而难的样本再用大模型,这样就能“性能好”的同时推理又快了,因为大部分模型只需要小模型推理即可。
区分样本
接下来的问题就是我们怎么区分样本是简单样本还是难样本了。这里我们将其换个思路:假如小模型对自己的结果非常有信心(确定),那我们就相信小模型的结果,反之,我们就将样本送进大模型,让大模型来进一步判断。注意,这里如果小模型非常“确定”的将样本给了错误结果,那这个结果也将认为是最终结果,即使这个结果送进大模型有被改正确的可能。那如何判断一个结果的不确定性呢?通常我们用熵来判断一个分布的不确定性,这里也一样。
模型参数共享
到了这一步,我们取得了“性能好”又“推理快”的目标了吗?其实还没有,因为此时我们会有多个模型,每个模型对应不同难易程度的样本,这样无疑是将推理从一次变成了多次,那怎么解决呢?我们可以利用上一个小模型的结果而不用再从头算,这样最终的模型就由一系列模型变为一个带有多个分支的大模型,只是每个分支的部分会进行一次判断,如果其结果的不确定性非常低,则直接返回结果而不再往后继续计算。而由于利用了上一层的结果,所以整体的时间上只增加了多个分类器与判断结果置信度的时间,而这个时间相对于其他计算要小的多。
整体架构
模型整体架构示意图: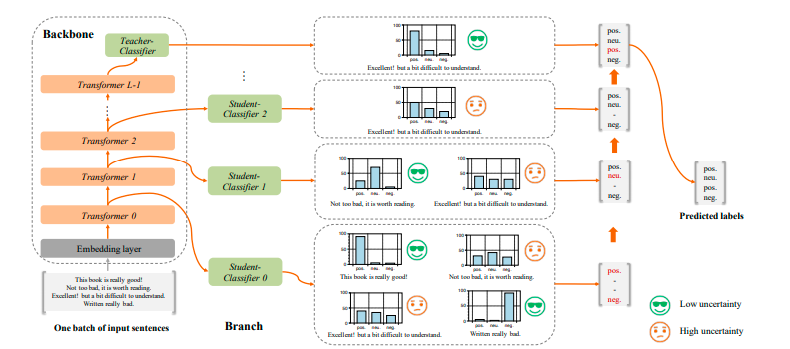
以上就是fastbert 模型的整体思路了。对于fastbert 来说,越靠前的层的性能越好,其推理速度提升的就越大,所以有必要尽量提高前面层的性能。这里就是Knowledge Distillation 的任务了:由于fastbert 本身就是一个12层bert,所以将最后一个分类器作为Teacher Model,然后生成对应的soft labels,然后迁移到fastbert 的每一个分支model上。之前的实验我们也提到过这种self-distillation 能提高性能,作者这里也是一样的思路。
复现
实验代码在fastbert感兴趣的同学可以看看.不过由于我只会keras(tensorflow),而tf 这种静态图不好实现这种分支结构,所以我的实验代码其实并没有真的提前终止计算返回结果,暂时没找到更好的实现方式,如果有知道的同学也欢迎告知。
总结
fastbert从思路上来说,通过对样本进行难易程度进行划分,对样本进行adaptive predict ,但是缺点也比较明显:1. 用确定性来代替难易,中间有不对等会导致较难样本在初期被错分后没有修正对机会;2.其基本假设是易分样本远多于难分样本,否则会使推理速度不降反增。
关于头图
芝麻街
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
