
训练加速篇(2)-horovod
horovod
horovod是Uber 团队开发的分布式训练框架,他可以满足让你尽量少的修改代码即可将在单卡训练的脚本横行扩展为多卡并行训练,同时又兼顾训练的加速。目前支持tensorflow/keras/pytorch/mxnet.底层通信主要依赖NCCL/Gloo(测试后NCCL是最快的),支持MPI(CPU 训练更快)。由于其训练加速效果比tensorflow 原生的distributedStrategy 快很多,所以在分布式训练时,推荐使用。
下面主要针对tensorflow1.x 下做分布式训练进行说明。
搭环境
环境主要依赖tensorflow1.x/horovod/nccl/mpi ,这里有两种方式搭环境:local/docker,下面分别介绍这两种环境的搭建及踩过的坑。
docker
由于谷歌官方的tensorflow1.x 不提供对A100/3090 及更新版本的显卡的支持,这里我们推荐使用nvidia 官方维护的nvidia-tensorflow,其提供了对A100/3090 等显卡的支持。支持pip/conda安装,同时也提供了对应的docker 镜像。
在使用镜像时,首先在ngc 中寻找最新镜像并pull 下来。
1 | docker pull nvcr.io/nvidia/tensorflow:22.04-tf1-py3 |
在启动时,建议设置share memory 为单张显卡显存差不多大小,否则有可能由于默认share memory size 太小(64M)导致nccl 通信时资源不足被kill。
1 | docker run -itd --gpus all --net=host --privileged -v /data:/data --name horovod --shm-size=32g --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/tensorflow:22.04-tf1-py3 |
local
在本地搭环境,主要需要安装nvidia-tensorflow/horovod/nccl/mpi,此外,由于nvidia-tensorflow 只支持ubuntu20.04,对应的OS 也要调整。
NCCL
安装NCCL,注意版本,为了兼顾A100,推荐使用v2.8.3-1 这个版本。
ref:nccl
1 | # 编译nccl |
验证一下
1 | # 确认horovod链接的nccl版本路径正确 |
mpirun
这里我们安装open-mpi
1 | # 安装依赖 |
nvidia-tensorflow
这里直接用pip 安装或conda 安装都行:
1 | pip install nvidia-pyindex |
horovod
horovod 在安装时,需要安装支持NCCL ,同时建议安装最新版本
1 | // 安装horovod |
验证一下horovod 使用了NCCL
1 | horovodrun --check-build |
对应的NCCL 前面勾选则支持NCCL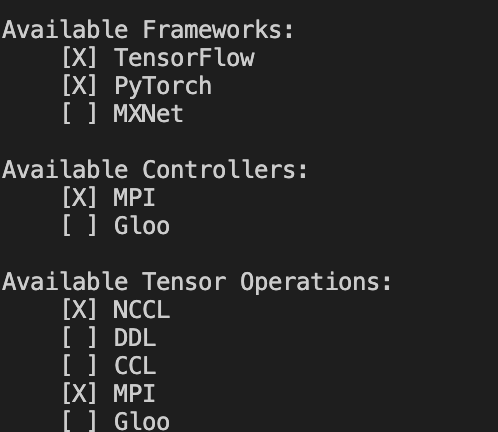
环境中踩过的坑
当前在A100 的机器上进行安装测试,其他型号显卡不一定也有同样的问题。
nccl
针对A100,ngc 的镜像中依然存在一个坑,其安装的nccl 版本太高,导致使用中会报错,对应的修复方式时对nccl 进行降级。
1 | # 下载编译nccl |
horovod
nvcr.io/nvidia/tensorflow:22.04-tf1-py3 中的horovod 不是最新版本的,在使用梯度累计时,老版本里有问题,对应的修复在新版本的horovd 中。所以,不管是否使用梯度累计,都建议升级一下horovod。PS: 升级时参考上面安装horovod 的办法 ,注意对NCCL 的支持。
代码层面修改
代码层面需要引入horvod,然后将optimizer 用horovod 进行wrap,此外,evaluate 相关的内容,尽量使用一个节点即可。
简单的demo:
1 | ... |
部分限制:
- 由于horovod 是让你在单卡的代码能够平滑的迁移到多卡上,所以这里的batch size 设置的是针对单卡的,但是整个优化过程是在多卡的结果上进行的,所以需要你手动调整自己的optimizer 以适应最终的batch size(batch_size_node * node_num)
- 需要使用梯度累计以达到更大batch size 的效果时,需要使用horovod 提供的方式,即:
1 | optimizer = hvd.DistributedOptimizer(optimizer, |
而直接使用bert4keras 中的实现方式会报错,具体原因未知。
3. callback 中只支持原生的keras 的操作,其他自定义的操作都会报错,如bert4keras 中的 Transformer.save_weights_as_checkpoint() 就不支持。
run code
1 | mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -mca btl_tcp_if_include eth0 -x LD_LIBRARY_PATH -x PATH python train_hvd.py |
其中 $-np$ 后面的参数是显卡数量,根据使用情况自行调整。
加速效果
对不同的OS 不同的环境进行了训练速度对比,效果如下:
| local system | run where | distributed | speed |
|---|---|---|---|
| centos | docker | tf-mirroredStrategy | 520 ms/step |
| centos | docker | horovod-without-nccl | 440 ms/step |
| centos | docker | horovod-nccl | 285 ms/step |
| ubuntu20.04 | local | tf-mirroredStrategy | 500 ms/step |
| ubuntu20.04 | local | horovod nccl | 265 ms/step |
| ubuntu20.04 | docker | tf-mirroredStrategy | 500 ms/step |
ubuntu20.04 |
docker |
horovod-nccl |
240 ms/step |
可以看到,相对于tf 原生的单机多卡的MirroredStrategy,能提速一倍之多,加速相当惊人了。
关于头图
可爱猫猫
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
