对比学习心路历程
前言
在之前的博客里,笔者介绍了在有监督任务(文本匹配)上,增加对比学习来提高模型性能的实验,而当时尝试后却发现,在新增了对比学习的任务后,模型的性能并没有得到对应的提升,经过简单分析后,笔者也尝试给出了一些可能的问题与解决方案。虽然笔者的实验都失败了,但是笔者依然认为对比学习是一个非常好的方向,所以也在持续关注,这篇就算是后续的填坑与总结吧。
对比学习范式
之前也提到过,这里在简单称述一下对比学习目前的主要范式。对比学习主要是通过对比,拉近相似样本之间的距离,推远不相似样本之间的距离。而相似样本的构造,又可以分为有监督与无监督两种:
- 有监督对比学习:通过将监督样本中的相同label的样本作为正样本,不同label的样本作为负样本,来进行对比学习;
- 无监督对比学习:由于没有监督信号(label),此时,我们对同一个样本构造两个view,让同一样本构造的两个view互为正样本,而其他样本构造的view则全部为负样本,以此来进行对比学习。而由同一个样本构造两个view,又是数据扩增的过程,所以也可以称作是数据扩展对比学习。而不管那种范式,通常对比学习都是在batch内进行。
无监督对比学习
笔者曾经在实验中,通过对样本进行eda(随机替换、随机删除、随机重复和随机互换),来构造不同view,由此进行对比学习。实验失败后,笔者也提到失败的可能原因主要有两点:batch size太小且样本上直接进行操作,获得的新样本与原来的语义可能由较大的差别甚至是完全的反义。如:“我不会再爱你” –> “我会再爱你”,而强行让这两个样本的语义距离相互靠近,效果自然不会好;而batch size太小的问题,一来是换大的GPU,二来可以尝试在算法层面进行优化,如将Adam 替换为AdaFactor,re-compute等,这不是本文的重点,所以就不再细说了。
而针对直接对样本进行修改会导致语义不一致的问题,其主要原因是NLP中,样本的输入是one-hot形式的,我们的相似样本应该是语义上相似,对应的修改后的语义距离应该尽可能“小”,而直接对one-hot形式进行修改,对应的距离恒定是$\sqrt{2}$ ,怎么看也不小。一种解决方法是借鉴对抗训练在NLP中的方式,将修改放在Embedding 层,由于one-hot与Embedding的对应关系,就能够获得“相似语义”的样本了。对应思路的论文有美团今年的ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer,总的来说,这篇paper就是将EDA的思路放在embedding 层,然后构建不同view后进行对比学习,最后获得的语义表示超过了当前的sota,在多个数据集上获得了提升。不过值得吐槽的是,美团也学坏了,竟然学会了谷歌那套在更多数据上进行训练然后跟只有原始数据的结果进行对比,可能是论文本身没什么亮点,只能通过“大的提升”来吸引眼球了吧~
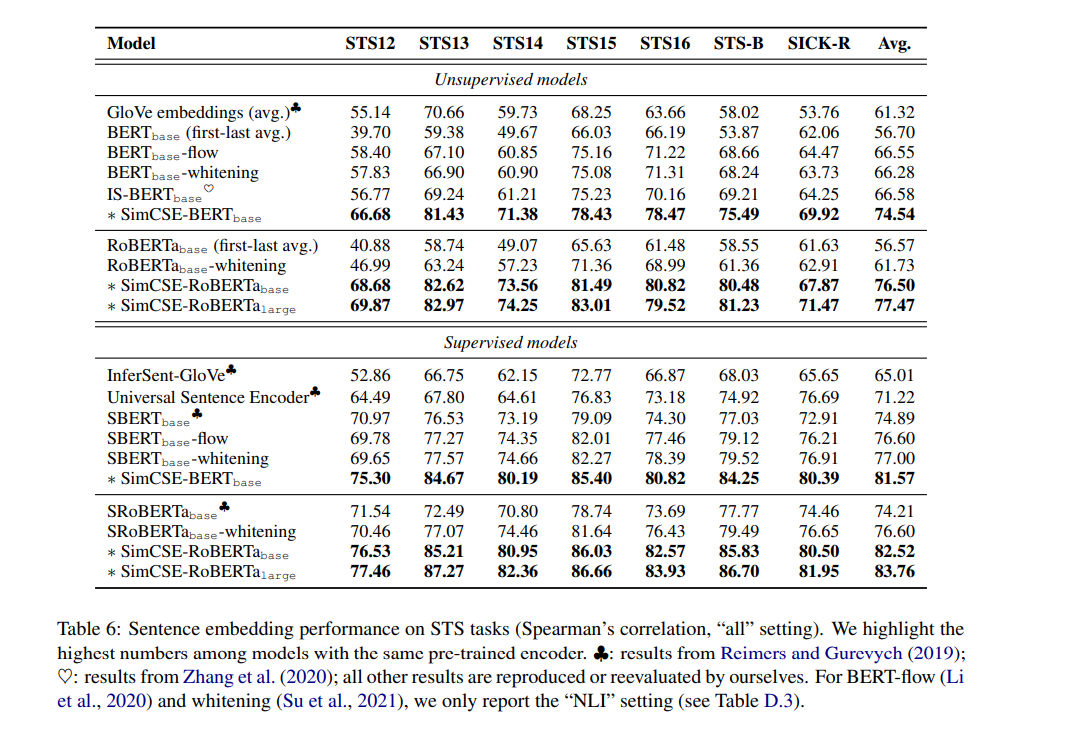
而做数据扩增时,最常用的两个方式随机删除与随机互换,而位置编码在transformer 中起到的作用不是关键性的,且直接互换位置也会带来语义变化较大的风险,那只使用随机删除策略做数据扩增,进行对比学习效果如何呢?答案是非常好!女神陈丹琦最近的论文SimCSE: Simple Contrastive Learning of Sentence Embeddings,只使用dropout ,对同一个样本构造两个不同的view,然后进行对比学习,最终的效果在非监督学习任务下8个点提升起步,在监督任务下4个点提升起步,此外,苏神在中文任务上也进行了实验,再次验证了该方法的有效性。
而simcse具体是如何工作的呢?其实做法相当简单,即将一个样本进入模型两次,然后通过dropout 两次,获得两个不同的view,互为正样本。而dropout 由于是在feature 维度进行随机mask,所以就得到了与在embedding层随机mask相同的效果,此外,由于在transformer 中,dropout 多次使用,也进一步的增加了两个view 的差异。读完论文,看着效果,直叹“大道至简”,而对比在embedding 做扰动与直接使用dropout,从效果上看dropout 也是一种更加有效的数据扩增手段。那这个思路是不是可以扩展到有监督任务呢?
其实读完SimCSE后,笔者就觉得dropout 是一种更加有效的数据扩增手段,自然可以扩展到有监督任务学习中。这里的有监督任务学习有别与有监督对比学习,请读者注意区分。而在有监督任务学习中的方案也是比较直观:将样本进入模型两遍,然后在做监督任务的同时,增加一个对比学习,不过笔者实验时被之前无监督任务的思路所束缚了,一直使用encoder output 的logits来表征语义,所以调来调去效果时好时坏,好的时候也没有超过0.5的提升,所以就放弃了。
而最近的论文R-Drop: Regularized Dropout for Neural Networks却成功的将这个思路延续了下来,在读完其代码后,才发现原来是自己姿势不对~
R-Drop中的完整思路是这样的:首先,我们通过将样本重复的输入到模型,然后通过dropout,获取不同的view,而dropout的目的是为了将集成模型的思路延续到深度学习中,本质目的是增加模型的鲁棒性。所以,不同的view获得的最终的输出,我们也希望其尽可能的一致。而论文中的任务都是分类任务,所以模型最终的输出是一个概率分布,衡量两个概率分别的差异通常使用kl散度,所以最终的loss增加了一个对应view之间的kl-divergence。
对比笔者之前的思路与R-Drop 中的思路,首先R-Drop 中是直接作用在最终的probs上,而笔者是希望encoder output logits 之间能“同性相吸,异性排斥”,而由于在做分类任务时,在logits 后都会接一个dense层来压缩维度,这个dense 层就会大大抑制前面的对比学习的效果,即前面的logits可以差异很大,但通过最后的dense层,却能得到一样的预测结果(label相同),而直接作用在最终的输出层,才会得到想要的效果;其次在R-Drop 中,不再需要与其他样本做对比,即只要相同view 的输出足够“接近”即可,而不需要其与其他的view 尽可能的“远”,考虑到同一个batch 内,存在同样label的样本的概率是极大的,而要求同时预测对label又要其结果之间尽可能不同是不合理的,所以取消掉与其他view之间的对比也是合理与必要的;而由于不需要去其他view做对比,对比学习中大batch size的要求也就不再需要,即在小的batch size 下该方法依然有效,真可谓“方法简单效果好”,在所有的NLP任务中都值得尝试。
前面提到笔者之前的思路的最大问题是对比的不是最后一层的输出,而同一batch内,又不可避免的会出现相同label,让相同label的logits之间相互“远离”似乎不太合理,但从对抗训练或者模型的鲁棒性上考虑,让同一样本的不同view之间相互接近而与其他view之间相互远离,可以达到让样本在一个范围内的输出尽可能的保持一致,从而能使模型更加的鲁棒,自然会增加一些泛化能力。这个思路笔者也在之前的实验上进行了修改尝试,结果显示确实能提高一些性能,但是与只拉近相同view之间的kl-divergence相比,提升就不够看了。
有监督对比学习
有监督对比学习是指相同label之间互为正样本,不同label间为负样本,与上文提到的有监督任务是不同的。而有监督任务中也可以使用无监督对比学习的思路,如上文提到的R-Drop,而有监督对比学习自从Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning后,笔者还未关注到有什么新的进展,所以还是推荐在有监督任务上使用R-Drop思路。
总结
本文主要总结了从笔者之前对比学习实验时留下的问题,到最近一些论文中提出的解决思路,虽然整个心路历程与原作者们的肯定不一样,但希望能给读者提供对比学习到目前为止的一些进展脉络。
关于头图
图片来自大佬刑无刀(陈开江)的朋友圈:据说人工智能中有80%的部分是人工😄
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
