
文档查重之SimHash算法
SimHash
不同网站间相互转载内容的情况非常常见,即使同一网站,不同的URL地址也可能对应相同内容,只是以不同的形式显示出来(不同的UI),而我们在爬取大量内容时,除了靠URL去重外,还需按文档内容排重
指纹可以判断人的身份,比如侦探把从犯罪现场采集的指纹与指纹库中的指纹做个对比,就能确定犯罪嫌疑人的身份。类似的,我们用一个文档的语义指纹来代表文档的语义,如采用一个二进制数组来代表。从而判断文档之间的相似性转化为判断两个语义指纹之间的相似性。
SimHash是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling 》中提到的一种指纹生成算法或者叫指纹提取算法,被Google广泛应用在亿级的网页去重的Job中,作为locality sensitive hash(局部敏感哈希)的一种,其主要思想是降维,即将一篇若干数量的文本内容用一个长度较短的数组来表示,而这个数组与这篇文档的主要的特征所对应。如在没有犯罪嫌疑人的身份证和指纹时,一个人的特征有无数多个,而我们可以通过调查犯罪嫌疑人的姓名,性别,出生日期,身高,体重,当天穿的衣服,外貌等一些主要特征来甄别嫌疑人的身份。simhash也是将复杂的特征,降维来简化。
SimHash计算过程: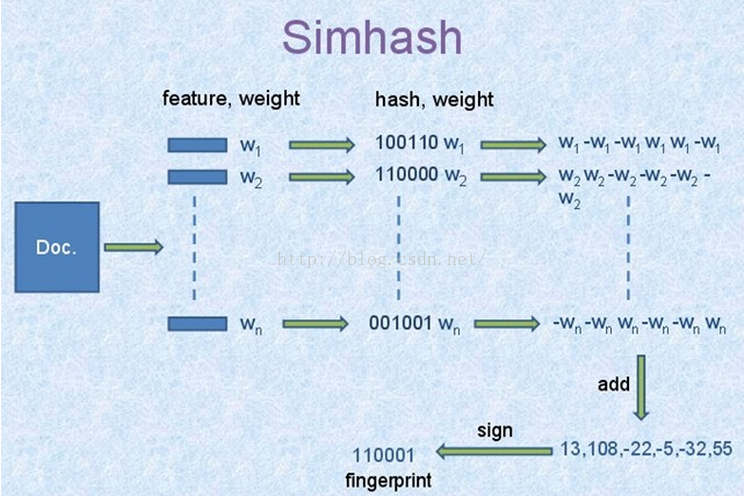
- 1.对文档提取特征及特征对应的权重
- 2.对特征进行hash,生成对应的hash值
- 3.hash值加权:对特征hash值的每一位做循环处理:如果该位值为1,则用weight代替,否则,用-weight代替
- 4.求和:将特征hash加权后的结果,按位求和,然后将结果按位二值化:大于0则为1,否则为0,即得到最后的SimHash值。
SimHash的计算依据是要比较的对象的特征,对于结构化的记录,可以按列提取特征;对于非结构化的文档,特征可以用全文提取topk关键词、标题、最长的几句话、每段的首句、尾句等。
1 |
|
海明距离
得到文档的SimHash值后,我们还需要判断两个文档是否相似。对相同长度的数字序列,我们采用海明距离来衡量其相似性。海明距离是指两个码字对应比特位(数字序列对应位置)不同的比特位个数。如1011101和1001001的第三位和第五位有差别,所以对应的海明距离为2。
计算两个数的海明距离时,我们先把两个数按位异或(XOR),然后计算结果中1的个数,结果就是海明距离。
1 |
|
把文档转化成SimHash后,文档的排重就变成了海明距离计算问题:给出一个f位的语义指纹集合F和一个语义指纹fg,找出F中是否存在与fg只有k位差异的语义指纹。
当k值很小而要找的语义指纹集合中的元素不多时,可以用逐次探查法:先把所有和当前指纹差k位的指纹扩展出来,然后用折半查找法在排好序的指纹集合中查找;
如果是面对的是海量的数据,且动态的增加,逐次探查法的效率将越来越慢。当k值较小,如不大于3时,我们使用一种快速方法。首先,我们将64位分成4份,当k为3时,则有一份中两者相等。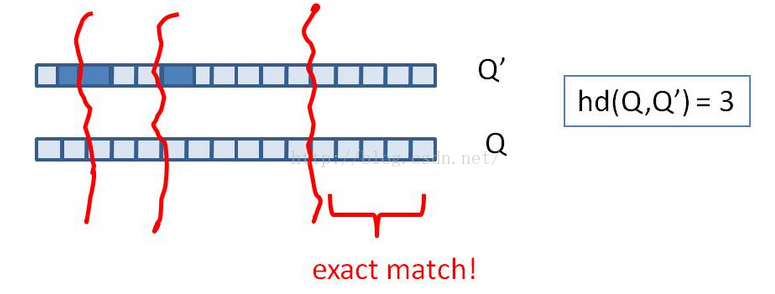
所以我们在存储时,将数据扩展为4份,每份以其中16位为k,剩余的部分为v,查找时精确匹配这16位。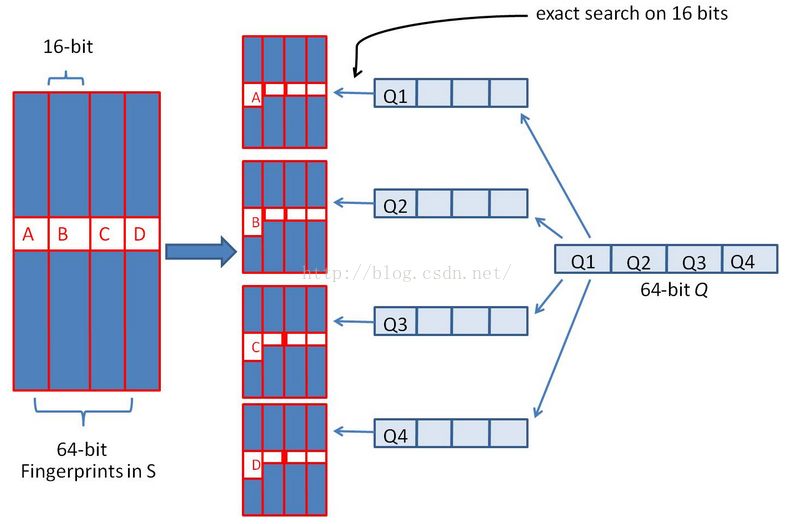
除此之外,对于一个已经排序的容量为$2^d$的f位指纹集合,由于指纹集合中有很多的位组合存在,所以高d位只有少量重复存在,所以在搜索时,也可以找出高d位与当前指纹相同的集合f‘,缩小查找份范围。
Simhash算法对长文本500字+比较适用,短文本可能偏差较大,最后使用海明距离,求相似,在google的论文给出的数据中,64位的签名,在海明距离为3的情况下,可认为两篇文档是相似的或者是重复的,当然这个值只是参考值,针对自己的应用可以自测取值。
关于头图
摄于河南老家冬雪
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
