
神经网络语言模型(NNLM)
统计语言模型
首先看一个例子:
ztc/ 上下/ 齐/ 拼搏/ ,誓为/ 春战/ 做/ 贡献
这句话呢通顺,意思明白,那如果换一下词的位置:
上下/ 齐/ 拼搏/ ztc/ ,春站/ 做/ 贡献/ 誓为
意思含糊了,但是大概意思还是能猜到,那如果在变换一下:
拼搏/ 齐/ ztc/ 上下/ ,贡献/ 誓为/ 做/ 春战
现在这句话已经不知所云了,如何判断这个由词序组成的序列是否符合文法、含义是否正确?
统计语言模型:一个句子是否合理,就看他的可能性的大小,即他的概率大小。
假设一个句子S,由一连串特定顺序的词$W_1, W_2,…W_T$ 组成,T是句子中词的个数,则S出现的概率$P(S) = P(w_1, w_2,…w_T)$
利用条件概率公式展开:
$P(w_1,w_2,..w_T) = P(w_1)*P(w_2|w_1)*P(w_3|w_1,w_2)*…*P(w_T|w_1,w_2,..w_{T-1})$
即: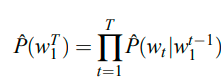
当语料中词典大小为100,000,句子平均长度为5时,需要学习的参数大概$100000 * 5 -1$ 个,为了降低计算复杂度,并考虑到词序列中离的更近的词通常在语义上也更相关,所以在计算时可以通过只使用前面n-1个词来近似计算,即n-grams: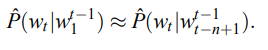
n-grams存在的问题:1.泛化时常常有训练语料中没有出现过的词序列;2.没有考虑词之间的相似性。
NNLM
- 1.对词库里的每个词指定一个分布的词向量
- 2.定义联合概率(通过序列中词对应的词向量)
- 3.学习词向量和概率函数的参数
why it works?
如果我们已知 “走” 和 “跑” 是相似词,那很容易通过 ”猫在屋里跑“ 推出 “猫在屋里走“,因为相似的词会有相似的词向量,而且概率函数是特征的平滑函数,所以特征的微小变化,只会对概率值产生一个很小的影响。即:1.相似词在特征空间距离更接近;2.概率函数是一个相对平滑的函数,对特征值的变化不是非常敏感。
所以训练语料中句子的出现不光增加了自身的概率,也增加了他与周围句子的概率(句子向量空间)
目标:$f(w_t ,··· ,w_{t−n+1}) = Pˆ(w_t |w_1,w_2,..w_{t-1} )$
约束:
- $∑ |V| i=1 f(i,wt−1,··· ,wt−n+1) = 1$
- 2.$f>0$
通过得到的条件概率进行相乘,得到词序列的联合概率.
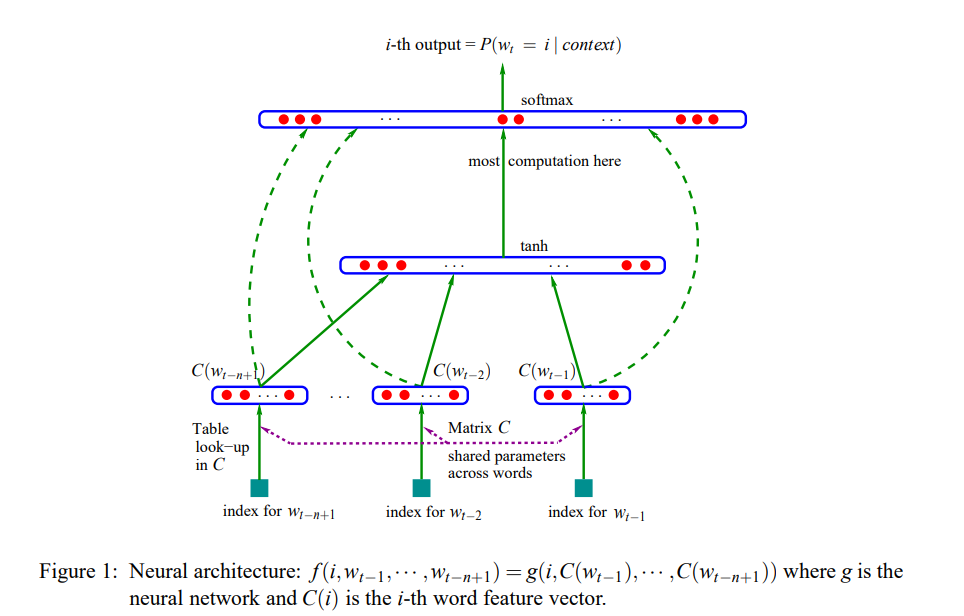
模型被分成二部分:
1.特征映射:通过映射矩阵 $C∈R ∣V∣×m$
将输入的每个词映射为一个特征向量,$C(i)∈Rm$ 表示词典中第 $i$ 个词对应的特征向量,其中 $m$ 表示特征向量的维度。
2.概率函数g
通过context中词的词向量来映射下一个词的条件概率。g的输出是一个向量,其中第i个元素表示了字典中第$i$个词的概率。完整的模型表达如下:
$ f(i,w_{t−1},··· ,w_{t−n+1}) = g(i,C(wt−1),··· ,C(wt−n+1))$
函数f由两个映射($g$ and $c$)组成,其中$c$由所有的上下文共享。
训练过程中的参数就由两个映射组成,设 $g$ 对应参数为$w$,$c$映射的参数就是自身,则 $θ=(c, w)$
训练过程就是学习$θ$的最大似然: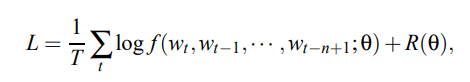
其中$R(θ)$ 是正则项。
模型中参数与字典大小V成线性关系,且与n(n-grams)成线性关系,不过可以通过共享结构降低参数数量,如延时神经网络或循环神经网络。
实验中,神经网络层只有一个隐层,有一个可选的词向量到输出的直连层,实际上就有两个隐层,一个共享的词向量$C$ 层,该层没有激活函数,还有一个tanh激活函数的隐层;最后的输出层是一个softmax层,来保证所有结果的和为1: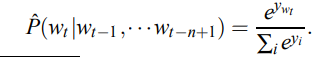
注意:第一层是没有非线性激活函数的,因为非线性激活函数会带来其他信息(联想神经网络中非线性激活函数),而正是这种直接的线性变换,才能让第一层的参数来作为词向量
用yi表示每个输出词的对数概率,则
$y = b+Wx+U tanh(d +Hx)$
其中x是词向量的拼接,$x = (c(wt-1),c(wt-2),c(wt-n+1))$
并行
参数与输入的窗口大小和字典的大小成线性,但是计算量却比n-grams 要大很多,首先n-grams中不需要每次都计算所有词的概率,只需要相关词频的线性组合,另外神经网络中主要瓶颈是输出层的激活计算。
out-of-vocabulary word
首先根据窗口上下文可能出现的词,进行加权求和初始化新词的词向量,然后将新词 j 加入字典,然后利用这部分数据集重新训练,进行retune.
后续工作
- 1,分解网络到子网络,如使用词聚类,构建许多小的子网络可能更快更简单
- 2,用树结构来表达条件概率:神经网络作用在每一个节点上,每个节点代表根据上下问得到该词类的可能性,叶子节点代表词的可能性,这种结构可以将计算复杂度从|v| 降低到 log|v|
- 3,梯度传播时可以只在部分输出词上进行,如某些条件下最相似的(如三元模型)。如果用在语音识别,可以只计算听觉上相似的词。
- 4,引入先验知识,如语义信息和语法信息。通过在神经网络结构中共享更多的结构与参数,可以捕获长期的上下文信息,
- 5,如何解释神经网络得到的词向量
- 6,上述模型对每个单词分配一个在语义空间的点,所以无法解决一词多义问题。如何扩展当前模型,在语义空间中为词分配多个点来代表词的不同语义。
作者提出的后续工作中,目前是很多人的研究方向,一些已经被证明有效。
- 第一个,优化网络结构,提到了从数据方向,构建更多的子网络,还可以直接对网络结构本身进行优化,如word2vec,将神经网络层去掉;
- 第二个,由于计算瓶颈在计算output的概率(对每个词计算概率,需要softmax归一化),所以提出可以通过树结构,来避免直接对所有词进行计算,如 Hierarchical Softmax
- 第三个也是在计算输出时,只通过一部分词来进行梯度传播,如负采样
- 第四个是通过共享结构,来捕获更多上下文信息,如GPT,Bert
- 第五个是如何解释,也是目前很多人的研究方向
- 第六个是一次多义的解决方法,如ELMO
参考:
http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf
关于头图
摄于望京soho
Buy me a coffee
如果觉得这篇文章不错,对你有帮助,欢迎打赏一杯蜜雪冰城。
